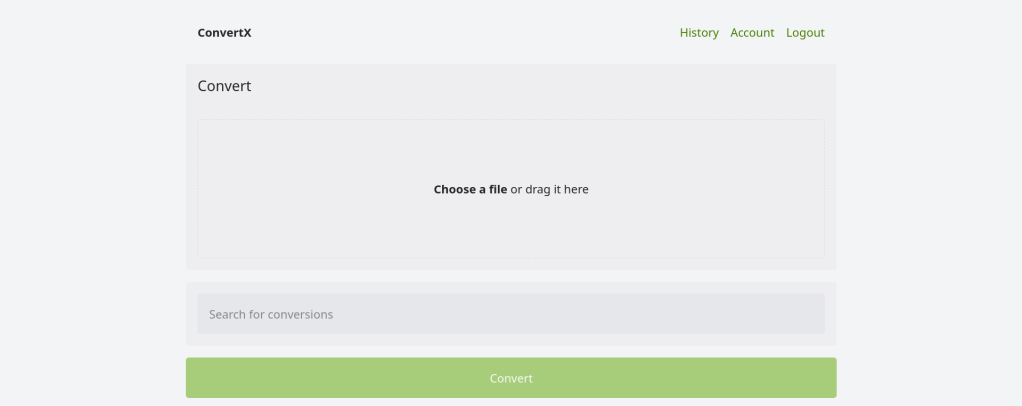
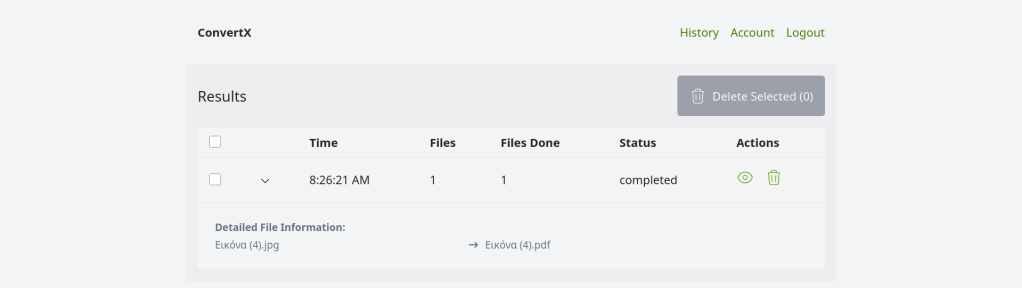
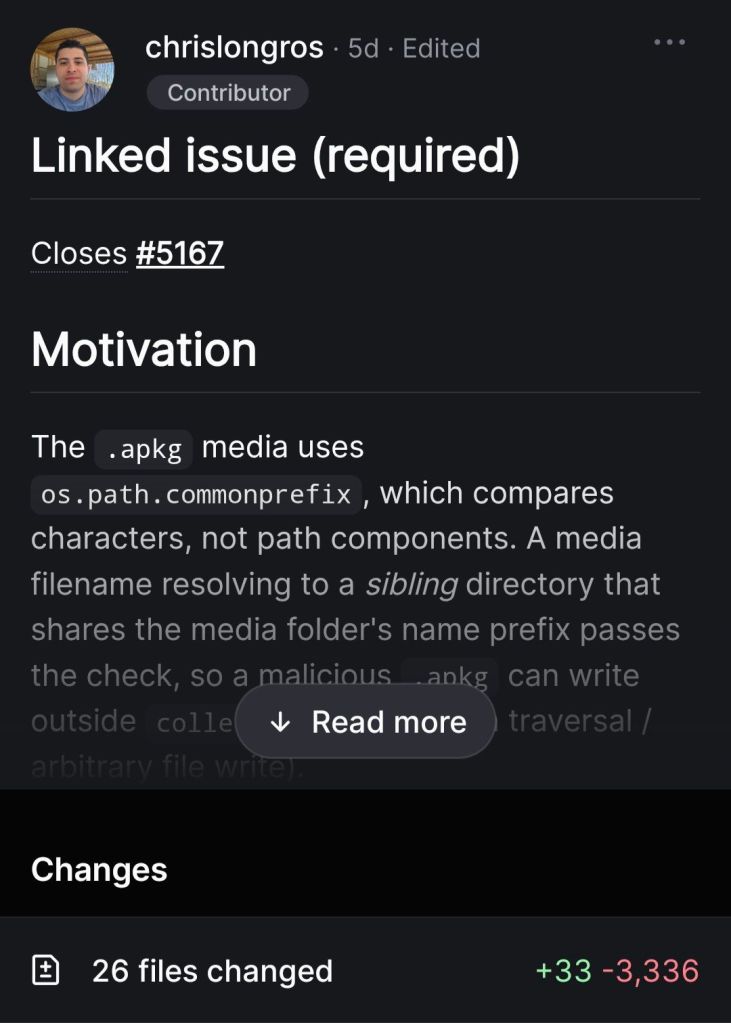
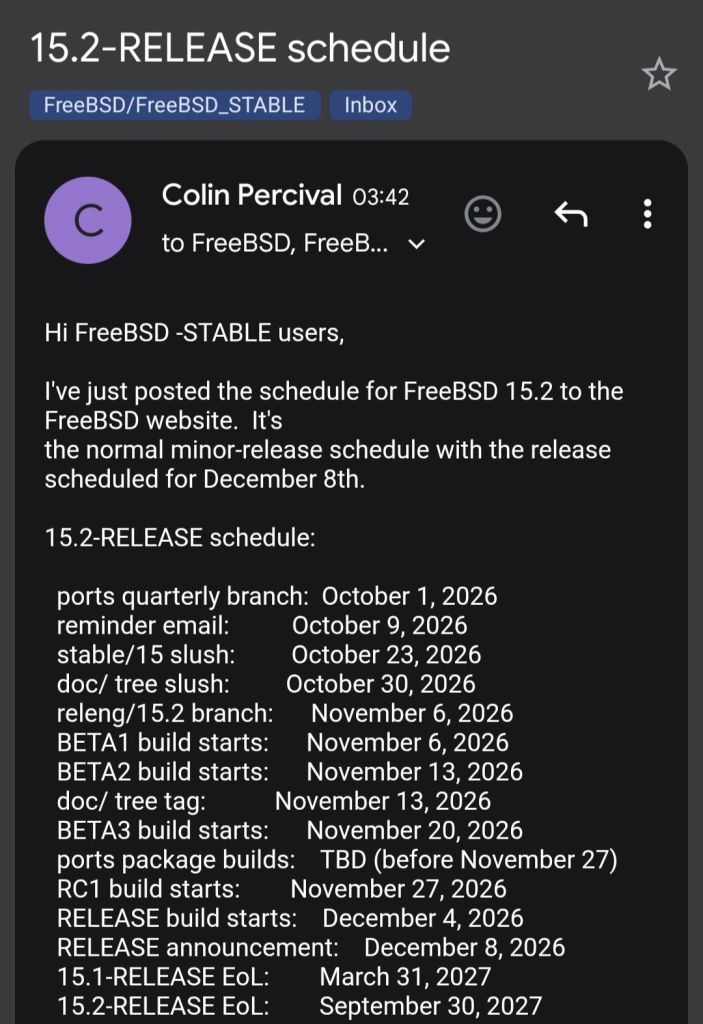
FreeBSD Q2 2026 Status Report — highlights
Published 27 July 2026, 41 entries. Full report · New RSS feed
- 15.1-RELEASE shipped 16 June; much of the quarter’s work landed against it.
- Foundation-sponsored commits: 638 src, 120 ports, 31 doc (up from 555/83/16 in Q1).
- DRM/graphics: port of Linux 6.12 LTS DRM drivers finished in time for 15.1; the 6.12.x patch series will be tracked going forward.
- ROCm: new effort to bring AMD’s compute stack to FreeBSD — currently unsupported at both toolchain and driver level.
- CPPC: restarted after the Halifax Hackathon — min/max/desired knobs for
hwpstate_intel(4),powerd(8)policies, a global EPP knob, and_CPC-conditional enablement forhwpstate_amd(4). - MPLS (GSoC 2026): phases 1–3 done — EtherType 0x8847 encapsulation with
netisr(9)dispatch, OpenBSD’sldpd(8)ported, and a forwarding engine with per-VNET LIB, verified end-to-end between VNET jails overepair(4). - Laptop support: Framework hackathon in Taipei — Panther Lake I2C/SMBus PCI IDs committed, work started on the RTL8159-based 10GbE adapter,
sysutils/framework-systemto 0.6.4. - Installer: subsystems, component framework and screens rewritten since EuroBSDCon 2025; TUI frontend near feature-complete.
- Also: CRA readiness and SBOM work, full CPUID control for bhyve, suspend/resume, hibernate, native S.M.A.R.T. retrieval, wireless updates, cluster refresh, Bugzilla improvements.